No artigo entitulado “Screaming Architecture”, Uncle Bob faz uma analogia entre a planta de um prédio e a arquitetura do software: a planta ilustra de forma clara quando se trata de uma casa ou de uma biblioteca. Sendo assim, uma boa arquitetura deveria deixar claro do que se trata o software (por ex, é uma aplicação de folha de pagamento?) em vez de deixar evidente quais frameworks foram usados para construí-lo.
Essa ideia fica bem sintetizada neste trecho do citado artigo:
So what does the architecture of your application scream? When you look at the top level directory structure, and the source files in the highest level package; do they scream: Health Care System, or Accounting System, or Inventory Management System? Or do they scream: Rails, or Spring/Hibernate, or ASP?
De outra forma, podemos dizer que uma boa arquitetura deveria basear-se nos use cases do software e não em seus frameworks. Esta é a base do que Uncle Bob viria a batizar de “Clean Architecture”, já mencionada neste artigo e que cobriremos em mais detalhes em artigos futuros.
Por hora, vamos focar na organização da estrutura de diretórios do projeto, de forma que os use cases – que definem o que o software faz – fiquem mais evidentes.
ORGANIZAÇÃO PADRÃO
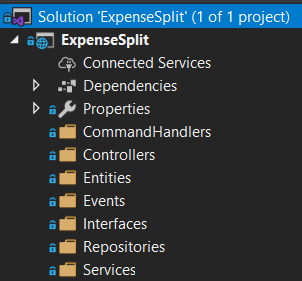
Comecemos pela estrutura na imagem ao lado, estimulada em artigos ou gerada automaticamente ao utilizarmos, por exemplo, o template padrão de algum framework.
A imagem, de uma solução .Net, não ilustra template algum, mas o enfoque em dar nomes aos diretórios de acordo com os tipos de objetos é um padrão bem comum. (Em algumas linguagens/frameworks, a estrutura é bem mais complexa do que a da imagem, com muito mais diretórios e sub-diretórios “soterrando” os use cases do software.)
Desta forma, a não ser pela “pista” deixada nos nomes da solução e da class library (linhas 1 e 2 da imagem), não há nada que “grite” do que se trata esta solução.
UMA OUTRA ABORDAGEM
Vamos considerar agora a divisão abaixo:
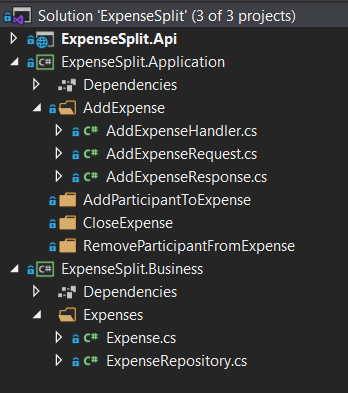
Percebam que na nova class library “ExpenseSplit.Application”, temos agora uma separação explícita por use cases. Pouco importa se você os chama de Command Handlers, Application Services, Interactors ou Transactions: cada um deles, juntamente com os DTOs relacionados, mora em seu respectivo diretório, o qual é nomeado de acordo com sua operação de negócio.
Veja o exemplo do diretório expandido “AddExpense”, que contém o interactor “AddExpenseHandler” e os DTOs de entrada e saída, respectivamente, “AddExpenseRequest” e “AddExpenseResponse”.
De forma similar, seguem os demais use cases separados nos diretórios “AddParticipantToExpense”, “CloseExpense” e “RemoveParticipantFromExpense”.
Na class library seguinte, “ExpenseSplit.Business”, estão os objetos de negócio e aqui precisamos de uma explicação mais detalhada. Em geral, um objeto de negócio pode ser utilizado em mais de 1 use case (por exemplo, a entidade “Expense” é utilizada nos 4 use cases ilustrados na imagem). Sendo assim, fica impraticável agrupar esses objetos por diretórios equivalentes aos use cases.
A abordagem utilizada, então, consiste em agrupar objetos que estão intimamente ligados, ou seja, que costumem trabalhar juntos. Em se tratando de um modelo rico e usando a terminologia vinda do Domain-Driven Design, cada diretório poderia corresponder a um Aggregate.
Na imagem, o diretório “Expenses” contém a entidade-raiz “Expense” e seu respectivo repositório, mas poderia conter outros objetos associados, como “ExpensePart”, que guardaria o quanto da despesa cada indivíduo deve pagar.
VANTAGENS DA ÚLTIMA ABORDAGEM
A segunda abordagem cumpre o objetivo de deixar o propósito do software (qual problema ele resolve), em primeiro plano: basta olhar a relação de use cases no primeiro nível de diretórios em “ExpenseSplit.Aplication”.
Por consequência, cada diretório (e seu equivalente namespace/pacote) é extremamente coeso, ficando mais fácil de encontrar e excluir os arquivos correlacionados. Um use case não faz mais sentido? Exclua seu diretório e não corra o risco de deixar algum DTO de request ou response orfão em algum outro lugar.
Outro ponto a considerar é que a organização padrão por categorias de objetos, ilustrada inicialmente, estimula uma má separação de responsabilidades entre as camadas do software. Afinal, um diretório “Models”, um exemplo comum nessa estrutura, se refere a que “model”? Como vários objetos de camadas diferentes do software costumam ficar no mesmo diretório, fica confuso de se entender qual faz parte de qual camada e mais fácil de criar dependências indesejadas entre eles. (A segunda abordagem remove ou, no mínimo, desestimula esses problemas.)
// NOTA: Para o benefício ainda maior desta abordagem, vale emprestarmos outra prática vinda do Domain-Driven Design, chamada de Linguagem Onipresente (Ubiquitous Language), de forma que possamos dar nomes coerentes com os nomes usados pelos especialistas de negócio. //
E AS CAMADAS DE DETALHES TÉCNICOS?
O foco do artigo está no “core” do software, isto é, os use cases e entidades/demais objetos de negócio, mas como fica a organização das camadas periféricas?
De modo geral, a organização do código segue por um caminho mais técnico, o que é bem natural neste caso. Alguns exemplos:
- Poderíamos ter uma class library “ExpenseSplit.Infrastructure”, que cuidaria da implementação de serviços como persistência, comunicação com APIs externas, mensageria e demais adapters de saída, organizados em diretórios como “Persistence”, “ExternalServices”, “Messaging”, etc.
- Outra class library “ExpenseSplit.Api”, que, por exemplo, implementa a API REST do software, poderia ser dividida em “Controllers” (e aqui cada um deles em seu respectivo sub-diretório junto com seus DTOs), “ErrorHandling”, “Authorization”, “Logging”, etc.
Notem que, mesmo que os nomes dos diretórios tenham um viés técnico, o agrupamento ainda é por “assunto” do que simplesmente por tipo de objeto. Por ex: o diretório “ErrorHandling” poderia conter quaisquer classes para este fim, sejam elas DTOs, classes que implementem uma interface específica do seu framework, etc.
CONCLUSÃO
Este artigo trouxe uma abordagem de organização de código inspirada na ideia de “Screaming Architecture” de forma que as funcionalidades do software, seus use cases, fiquem mais evidentes dentro da solução.
Desta forma, ganhamos mais clareza no código e diretórios/pacotes mais coesos e mesmo os componentes de viés técnico podem se beneficiar dessa organização, agrupando arquivos por responsabilidades específicas.
No entanto, é muito importante entender que esta simples organização do código NÃO garante a implementação correta de um estilo de arquitetura, como a citada “Clean Architecture”. Para que a arquitetura seja implementada corretamente é necessário que haja determinadas restrições na forma como cada camada se comunica com a outra (vimos um pouco desse assunto <aqui> e voltaremos em artigos futuros).
Agora, digam aí: como costumam organizar o código? De uma das formas mostradas aqui? De outra maneira? Dúvidas, críticas, sugestões? Comentem ai!

Participe! Vamos trocar uma ideia sobre desenvolvimento de software!